Este post es la versión escrita de la ponencia que Gianluca Fiorelli presentó a The Inbounder World Tour Madrid, el pasado 17 de Marzo
Quién me conoce - o simplemente me sigue en las redes sociales - sabe que soy un friki de la ciencia ficción, lo cual no es de extrañar en un hombre que en su niñez vió “Las Guerras de las Galaxias” en el cine o la serie original de “Battlestar Galactica” en televisión.
Uno de los personajes siempre presentes en series, películas y novelas de ciencia ficción son los robots. Estos seres mecánicos con inteligencia humana o sobre-humana siempre nos han fascinado. Si observamos la historia del cine podemos encontrar robots algo ingenuos, como el Hombre de Hojalata de “El Mago de Oz”, otros más peligrosos, como Ava en “Ex-Machina”, o más humanos que los humanos, como el mítico Roy Batty de “Blade Runner”. Independientemente de su función dramática en las tramas, la característica común de todos los robots es que son nuestros sustitutos.
Perspectivas sobre el impacto de los robots en nuestros trabajos

Credit: Westworld de HBO
Más allá de la fascinación que nosotros sentimos hacía nuestros sustitutos de piel sintética, la problemática relación entre humanos y robots se ha colocado en el centro de las discusiones sobre el futuro que nos espera. La evolución de la robótica, de hecho, ha tomado tal velocidad de crucero que lo que parecía ser solamente ciencia ficción, ahora ya puede ser – si no lo es ya – realidad.
The First Industrial Revolution devalued muscle work, then the second one devalued routine mental work. (“La Pianola” de Kurt Vonnegut, 1952)
Kurt Vonnegut lo previó en 1952 en su novela “La Pianola”: un mundo donde la gran mayoría de la población mundial no trabaja porque era sustituida por las máquinas, perdiendo el control sobre sus vidas. Su visión distópica del futuro - que en el fondo escondía algo de ironía sobre el entusiasmo por la evolución de la ciencia y la tecnología típica de la sociedad americana de los 50 - es común en la ciencia ficción.
En realidad, a lo mejor no nos espera un futuro a lo 'Terminator' ni tampoco llegaremos a ser aquellos cruceristas gordos que son los humanos que tanto añora Wall-e en la película de Pixar, pero es verdad que todos los estudios más recientes sobre el impacto de la robótica sobre el mundo del trabajo apuntan en la dirección indicada por el gran científico Stephen Hawking: “The automation of factories has already decimated jobs in traditional manufacturing, and the rise of artificial intelligence is likely to extend this job destruction deep into the middle classes, with only the most caring, creative or supervisory roles remaining.”
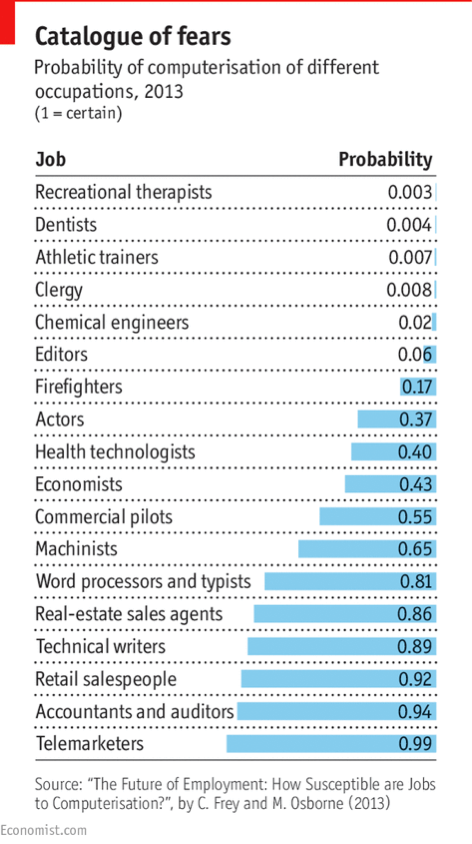
Esta preocupación y, por ende, la necesidad de intervenir para equilibrar (si no contrastar) este futuro sin trabajo no es nueva. En 1962, el mismo presidente estadounidense John Fitzgerald Kennedy indicaba como un deber del estado “mantener el pleno empleo al mismo tiempo que la automatización está remplazando a los trabajadores humanos”. Y no muy diferente era la preocupación que el economista Keynes, en los años 30 del siglo pasado, expresaba cuando acuñó la definición de “desempleo tecnológico”.
Pero, ¿de verdad tenemos que preocuparnos? La respuesta es sí. Si tomamos como ejemplo el impacto que los robots y la automatización tendrán en el mercado laboral estadounidense, podemos ver como el 43% de la población activa de los EEUU está en riesgo de ser sustituida por las máquinas. Si decir 43% no impresiona, a lo mejor sí lo hace decir que 87.720.000 trabajadores irán al paro en los próximos años en Estados Unidos a causa de la robótica.
Es verdad que existen otros estudios menos pesimistas y que, por el contrario, indican que también se construirán trabajos – muchos de los cuales ni sabemos cuáles son – que irán sustituyendo a los perdidos. Esta visión positiva se basa, además, sobre lo que siempre ha pasado en situaciones similares como, por ejemplo, cuando el vapor sustituyó la fuerza muscular de hombres y animales durante la Primera Revolución Industrial. Pero el problema es que la creación de nuevos trabajos no va al mismo ritmo que la destrucción de los viejos o, por lo menos, no asegura su relevo completo.
Si volvemos a examinar el listado de la gráfica anterior, los trabajos que más se consideran en riesgo por la automatización son, en su gran mayoría, empleos en los que los elementos rutinarios son mayoría.
¿Los trabajos en la industria del marketing web también están en peligro?
A primera vista, nosotros - los digital marketers - podríamos estar tranquilos. De hecho, si pensamos en los robots en cuanto a máquinas como tales, tienen más motivos para preocuparse los perros pastores, ya que existe en la actualidad un robot – SwagBot – pensado para reemplazarlos.

Pero, si pensamos en la automación también como sistemas de software que facilitan y hasta sustituyen a los operadores humanos gracias a su indudable mayor capacidad de cálculo, entonces las cosas empiezan a ser menos ciertas.
La automación en el marketing, en realidad, no es algo nuevo. ¿Quién no conoce o no ha utilizado softwares cómo Zapier o IFTTT para automatizar tareas mecánicas como guardar en Dropbox los ficheros que recibimos en nuestros correos? Muchas de las herramientas que utilizamos a diario - desde Answerthepublic para las búsquedas de palabras clave hasta los mismos sistemas de marketing automation como Hubspot o Pardot - son softwares que nos libran de realizar tareas repetitivas haciendo nuestro trabajo no solamente más veloz, sino más eficaz.
Los instrumentos más a la vanguardia tienen su base en técnicas que están hoy en boca de todos:
- Machine Learning;
- Deep Learning;
- Inteligencia Artificial.
El problema es que, en realidad, muchas veces existe confusión entre un término y otro, así que permitidme aclararlos.
Primero: evitar malentendidos
Inteligencia Artificial

Cuando hablamos de inteligencia artificial, hablamos de sistemas informáticos capaces de realizar tareas que normalmente requieren inteligencia, tales como la percepción visual, reconocimiento de voz, toma de decisiones y traducción entre idiomas. Existen, además, tres diferentes tipos de Inteligencia Artificial, como bien explica Tim Urban en su artículo 'La Revolución de la Inteligencia Artificial: el camino a la Superinteligencia':
- ASI (Artificial Super Intelligence), que oscila entre un equipo que es solo un poco más inteligente que un ser humano a otro que es billones de veces más inteligente. Afortunadamente este tipo de IA todavía existe solo en la ciencia ficción.
- AGI (Artificial General Intelligence), una máquina que puede realizar cualquier tarea intelectual que realice un ser humano. Crear una AGI es una tarea objetivamente muy compleja, sin embargo, gracias a las investigaciones de empresas como DeepMind de Google, podríamos estar a punto de hacerla realidad.
- ANI (Artificial Narrow Intelligence), en la que la Inteligencia Artificial se especializa solamente en una área. Esta es la IA que ya existe y a la que Google mismo se refiere cuando dice – por ejemplo, cuando anunció RankBrain – que se sirve de la IA para mejorar sus productos como su buscador.
Machine y Deep Learning
El Machine y el Deep Learning frecuentemente se utilizan como sinónimos de Inteligencia Artificial cuando, en realidad, no lo son. Son técnicas que se utilizan con el fin de llegar a dotar a las máquinas de Inteligencia Artificial.
¿Qué es el Machine Learning?
El Machine Learning es la técnica más comúnmente utilizada hoy en día y, en su versión más básica, es la práctica de usar algoritmos para analizar datos, aprender de él y luego hacer una determinación o predicción acerca de algo en el mundo. Así que, en lugar de la codificación manual de rutinas de software con un conjunto específico de instrucciones para llevar a cabo una tarea en particular, la máquina es "entrenada" utilizando grandes cantidades de datos y algoritmos que le dan la capacidad de aprender a realizar la tarea asignada.
Ejemplo de esquema de proyecto basado en Machine Learning
Un buen ejemplo de uso de Machine Learning es el filtro llamado Panda, que Google tiene implementado en su algoritmo para poder mejorar la calidad de sus resultados de búsqueda. También a nivel de software para marketing podemos encontrar ya herramientas que se basan en Machine Learning para poder realizar todos los complejos cálculos que están en la base de su funcionamiento.
Dos ejemplos españoles de software de este tipo son Safecont, que tiene como objetivo medir si un sitio web está en riesgo de penalización por baja calidad según Google, y Adinton, que utiliza el Machine Learning para poder ofrecer los mejores datos de atribución de las conversiones y, en lo específico del marketing de pago, las pujas ideales que se deberían utilizar para poder obtener el ROI máximo de una campaña.
¿Qué es el Deep Learning?
Definir de forma simple qué es el Deep Learning no es tarea fácil, sobre todo porque existen muchas, así que me limitaré a reportar las definiciones más comunes:
- Usar una cascada de capas con unidades de procesamiento no lineal para extraer y transformar variables. Cada capa usa la salida de la capa anterior como entrada. Los algoritmos pueden utilizar aprendizaje supervisado o aprendizaje no supervisado, y las aplicaciones incluyen modelización de datos y reconocimiento de patrones.
- Estar basados en el aprendizaje de múltiples niveles de características o representaciones de datos. Las características de más alto nivel se derivan de las características de nivel inferior para formar una representación jerárquica.
- Aprender múltiples niveles de representación que se corresponden con diferentes niveles de abstracción. Estos niveles forman una jerarquía de conceptos.
En otras palabras, el Deep Learning se basa en crear un algoritmo de base que se basa sobre otros algoritmos y que, a su vez, es capaz de crear otros más para conseguir el objetivo designado.

Los primeros ejemplos de uso de Deep Learning de Google consistían en crear algoritmos capaces de reconocer gatos en los videos de YouTube.
Si hablamos de aplicaciones prácticas del Deep Learning, TensorFlow – gracias también a ser un código abierto – es el instrumento más común. Un buen ejemplo de su uso es lo que hizo la agencia británica Distilled, la cual lo utilizó para crear DeepRank, un sistema con el cual es posible prever qué página web tiene más probabilidad de posicionarse mejor simplemente dando al mismo DeepRank sus urls para examinarlas:
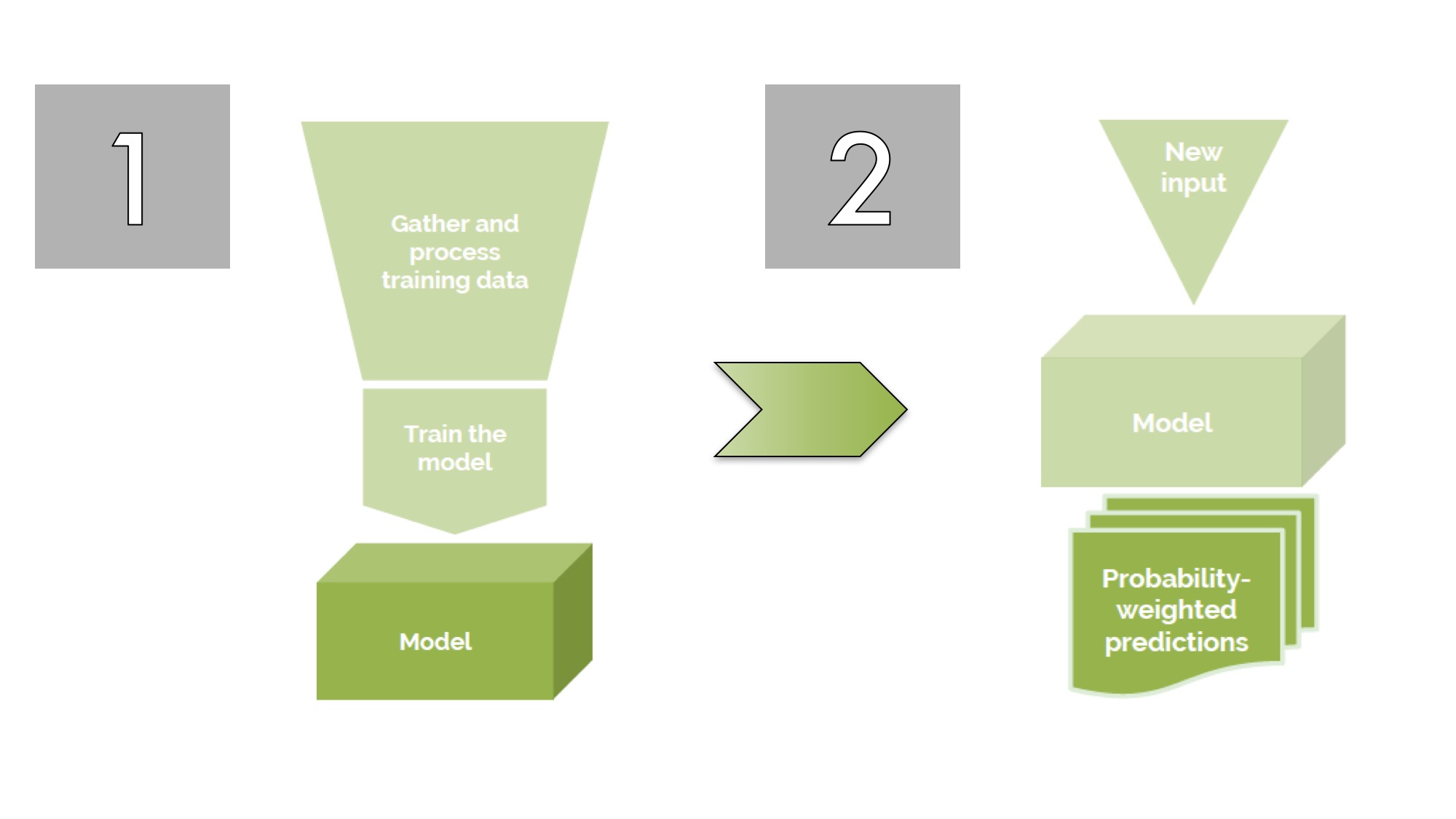
Esquema de funcionamiento de DeepRank
Los resultados de tal experimento fueron tales que DeepRank se mostró mucho más eficaz al evaluar el potencial de posicionamiento de una página con respecto a otra que evaluaban los SEO más experimentados. Así que la pregunta sobre si nuestros trabajos, que nos parece tan seguros y tan “novedosos”, están en peligro vuelve con mayor fuerza todavía después de los ejemplos mostrados hasta ahora de softwares basados en inteligencia artificial.
En Social Media Marketing, todos los Community Manager especializados en Social Customer Care deberían empezar a mirar con recelo a la evolución de los chatbots, que se están desarrollando más y más (sin algunos problemas, a decir la verdad) en plataformas de mensajería instantánea como Facebook Messenger o Whatsapp. Igualmente, los Account Manager de las agencias, que normalmente dedican gran parte de su trabajo a crear reportes para sus clientes, deberían saber que existen programas como NarrativeScience, que son capaces de crear reportes mucho más velozmente que ellos y con la misma eficacia.
Además, también si pensamos que no estamos “en peligro” porque nuestros trabajos son menos rutinarios y más creativos, deberíamos estar menos confiados. Por ejemplo, desde hace algún tiempo, la editorial Condé Nast utiliza los softwares basados en Inteligencia Artificial de IBM Watson para individualizar qué influenciadores targetizar entre decenas de miles de perfiles en redes sociales, no a grupo de expertos de Social Media.

¿Este anuncio lo creó un algoritmo o un creativo humano?
Finalmente, ya existen hasta ejemplos de anuncios publicitarios creados exclusivamente por algoritmos que, dicho sea de paso, hasta un 46% de un público utilizado como test consideró mejor que el anuncio creado por un creativo humano.
Cambiar de modelo para no quedar atrás
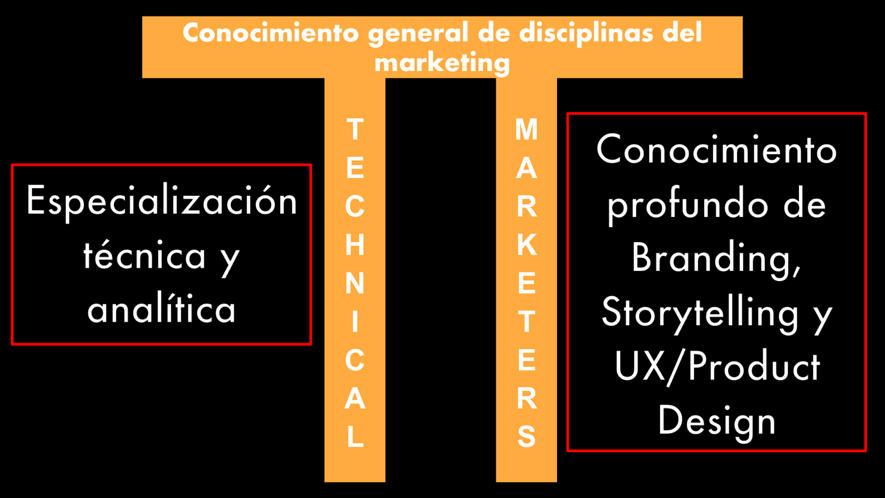
Desde hace unos años, en el marketing digital se ha impuesto la figura del T-Shaped Marketer, es decir, un profesional que, si bien tiene un conocimiento básico de las disciplinas del marketing online más cercanas a su trabajo cotidiano, se hiper-especializa en una disciplina única o hasta solamente en unas pocas áreas de su disciplina principal de trabajo:
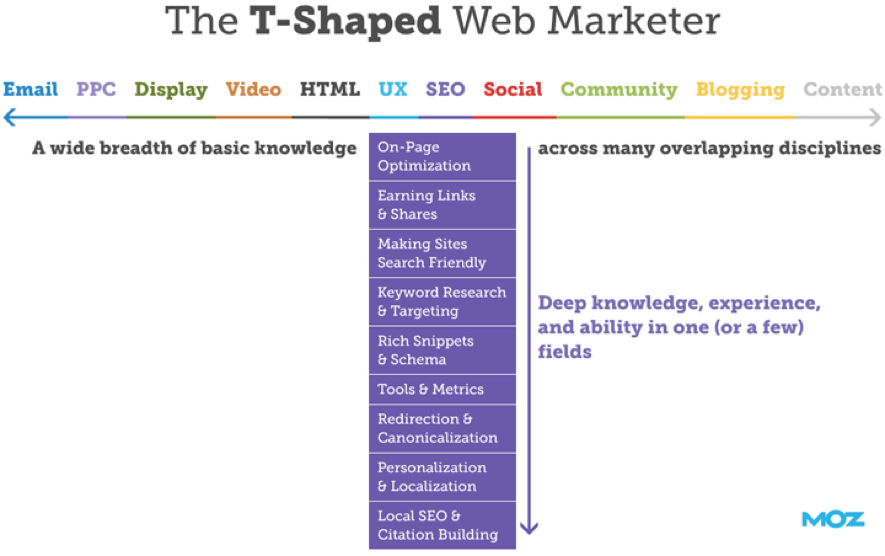
Con el advenimiento de técnicas y softwares basados en Machine y Deep Learning, este modelo empieza a mostrar debilidades porque, como está demostrado, cuanto más especializada es la tarea, tanto más una maquina la puede hacer. Es decir, si somos hiper-especializado en una o pocas tareas como - por facilitar solo un par de ejemplos - el optimizar el SEO de unas páginas (el mal llamado SEO Copywriting) o en la Búsqueda Semántica, entonces tendremos más probabilidad de ser remplazados por softwares que sabrán hacer nuestro trabajo por lo menos igual de bien que nosotros, pero más velozmente y más económicamente.
Todos los estudios hechos hasta ahora también nos dicen que los algoritmos son (todavía) débiles en replicar decisiones tomadas sobre datos no estructurados: es decir, no tienen todavía la capacidad de intuir creativamente soluciones basadas en sus análisis.
Esta gran diferencia existente entre nosotros y los algoritmos pueden darnos la solución a las dudas sobre nuestro futuro y sugerirnos pasar a un nuevo modelo: el P-Shaped Marketer, una figura que acaso IBM misma está relanzando como la ideal para los tiempos venideros.
Además, el P-Shaped Marketer – donde el P está por π – es el modelo que mejor se corresponde a la verdadera naturaleza de los profesionales del marketing digital: ser Technical marketers. En otras palabras, no es o nosotros o los robots, sino nosotros con los robots.
Ejemplos e ideas del nuevo marketing online
SEO, Keyword Research y Lenguaje Natural
Los más recientes estudios están mostrando cómo las Búsquedas Vocales, también favorecidas por el uso de los móviles inteligentes, han llegado a representar ya el 20% de todas las búsquedas realizadas en Google. Además, más allá de lo que “oficialmente” los Googlers afirman, parece que unas de las características de los últimos updates de Google es la relevancia entre intención de búsqueda y las páginas que se posicionan para las búsquedas mismas.
Esta evolución, tanto en cómo la gente busca cuanto en cómo interpreta el contenido de los documentos online, hace que las técnicas más tradicionales de keyword research se estén quedando cada día más obsoletas.
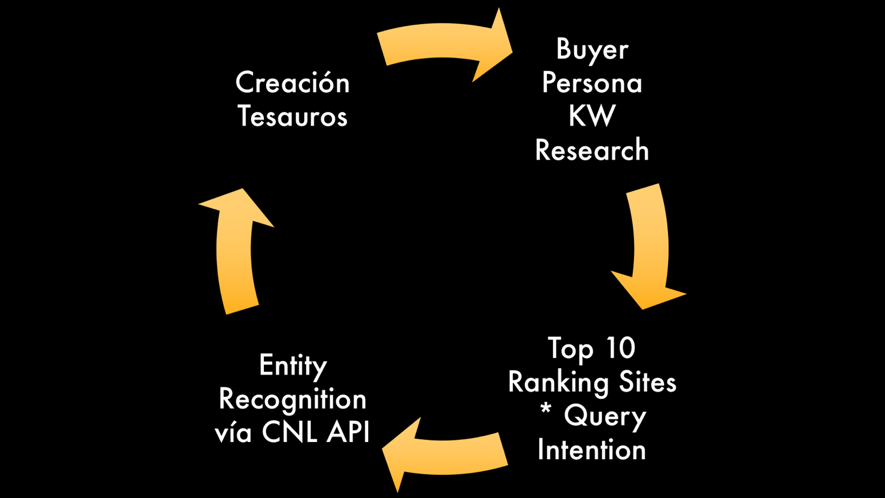
Unas de las soluciones más eficaces, entonces, es acudir a instrumentos basados en Machine y Deep Learning como, por ejemplo, el Cloud Natural Language API desarrollado por el Natural Language Understanding Team de Google.
Gracias a sus API, podemos realizar un exhaustivo análisis sintáctico, de sentimientos y de entidades de las páginas web que se están posicionando en el Top 10 para las palabras clave que hemos individualizado en un primer estudio.
Gracias a este análisis, podemos individualizar:
- El “diccionario” común utilizado por estas páginas, que podremos utilizar también nosotros para optimizar nuestros textos;
- El tono de voz que mejor se corresponde a las intenciones que tienen las búsquedas de los usuarios;
- Las entidades que normalmente se referencian cuando se habla sobre el tema por lo que se posicionan las páginas en el Top 10 para una búsqueda determinada y que, por lo tanto, se consideran relacionadas semánticamente a aquella misma búsqueda.
Además, si estamos realizando un análisis en el ámbito de SEO Internacional, gracias a otras API de Google basadas en Deep Learning – las Cloud Translation API – podemos replicar un análisis de este tipo en otros idiomas con mucha más facilidad y, sobre todo, velocidad.
Lo más interesante es que podemos realizar todo esto también sin tener que programar nada, sino simplemente utilizando una herramienta como MonkeyLearn.
SEO y optimización del enlazado interno mejorada con algoritmos de Machine Learning
Todos los SEO saben que una de sus “armas secretas” es una buena optimización del enlazado interno. Esta tarea no es simple y, para llevarla a cabo de una manera realmente efectiva, es necesario analizar con mucho detenimiento cosas como los logs de los servidores, el comportamiento de los usuarios dentro de las páginas, las métricas de conversión y, finalmente, métricas SEO como tráfico desde búsqueda orgánica, posicionamiento medio y otras.
Se trata, en definitiva, de una tarea que, si cuesta horas de esfuerzo y trabajo solo para un site pequeño o mediano, para uno potencialmente enorme como un comercio electrónico o un sitio de noticias puede llegar a ser tan complejo que, finalmente, muy pocos realmente se empeñan en optimizar este aspecto tan importante del SEO de un sitio web.
SEO y optimización de CTR de los Search Snippet
Una de las tareas más “odiadas” por aburrida entre los SEO es la optimización de los elementos Title Tag y Meta Description. De hecho, sobre todo cuando nos encontramos trabajando en un sitio web con miles de páginas, la tendencia es crear unos metatags de base que, aplicando unas simples reglas, se pueden adaptar prácticamente para casi todo tipo de página. Pero esta clásica práctica no siempre se puede aplicar con sentido.
Además, nos obliga a crear meta descripciones poco eficaces a nivel de atracción del clic en el resultado de búsqueda de parte de los usuarios y esto, como algunos experimentos parecen confirmar, puede llegar a ser perjudicial a nivel SEO, a parte - obviamente - de ofrecer resultados a nivel de tráfico a veces muy por debajo de los que la posición misma de una página en los resultados de búsqueda podría obtener.
Afortunadamente, desde algún tiempo existen algoritmos como Summarizer – disponible en el portal de algoritmos Algorithmia – que nos facilitan esta tarea. Basándose en reconocimiento semántico, Summarizer consigue lo que promete con su propio nombre: crear resúmenes con sentido de bloques también muy grandes de texto. Pensad lo que esto puede suponer en calidad de trabajo y ahorro para el SEO y, además, para todo escritor al que se le pide crear extractos de artículos y posts.
Toda disciplina del marketing web y el reporting
Si existe una actividad que, si bien necesaria, es un agujero negro de horas de trabajo para todo marketer, es la de redactar los informes para los clientes. De hecho, tan onerosa es esta tarea a nivel de horas de trabajo real, que prácticamente todas las herramientas que utilizamos nos ofrecen la automatización de esta fase.
El problema surge cuando tenemos que juntar reportes de naturaleza diferente porque, obviamente, no existe un estándar y toda herramienta tiene su manera, también gráfica, de crearlos. Finalmente, entonces, no es tan raro el vernos obligados a crear plantillas en Excel después haber coleccionado hasta decenas de ficheros .csv diferentes. Sin embargo, los algoritmos basados en Lenguaje Natural pueden ayudarnos también en esta tarea con herramientas como Wordsmith, que tiene la capacidad de leer e interpretar ficheros Excel, Google Sheet, Tableau y Zapier y transformarlos – eso sí, después que hayamos dado unas simples reglas iniciales – en un reporte escrito.
SEO, Content Marketing, Content Strategy y la optimización de bancos de imágenes

Unos de los ámbitos en los que el Deep Learning ha mostrado todo su potencial es en reconocimiento e interpretaciones de las imágenes. Ahora las máquinas son capaces de reconocer qué se retrata hasta en las fotos más borrosas, al más puro estilo cine de acción estadounidense. En concreto, lo que hacen todos los programas basados en reconocimiento de imágenes es etiquetar las imágenes mismas con los elementos presentes en ellas.
Un ejemplo ya clásico es Facebook: si vamos a ver el código de una página de Facebook, podemos ver como este etiqueta todas las imágenes que nosotros subimos basándose en algoritmos, así que si subimos la foto de un perro que juega con una pelota, Facebook etiquetará la foto con – justamente – “perro” y “pelota”.
La razón final de este etiquetado es, para Facebook, el poder entender mejor los contenidos que todos nosotros subimos en nuestros muros y, así, recopilar datos que pueden ser luego utilizados por Facebook y sus anunciantes para 'targetizarnos' mucho mejor.
Poder satisfacer una exigencia de este tipo también está detrás de los muchos usos que se pueden hacer de una herramienta como Clarifai o de algoritmos libres como Altify.
Pero estos no son los únicos usos que podemos darle a los algoritmos de reconocimiento de imágenes. Pensad, por ejemplo, cómo estos pueden facilitar el trabajo de clasificación y, finalmente, de utilización de bancos de imágenes enormes como los que poseen los sitios de news o de venta de stock de imágenes.
Ecommerce y personal shopping online mejorado gracias a los algoritmos de Machine Learning
Ya es posible poder ofrecer a los usuarios de un Ecommerce la posibilidad de ir comprando cosas acompañados por un robot que nos ayuda a comprar mejor y más velozmente lo que estamos buscando. Un ejemplo es lo que hace The North Face en su sitio web gracias a la ayuda de IBM Watson. Como podéis ver en el screencast aquí abajo, nosotros mismos instruimos al algoritmo con cada compra y este, basándose también sobre reglas fundadas en las mismas categorizaciones de los productos y filtros establecidos, y cruzándolo con datos abiertos como los de las previsiones del tiempo, es capaz de proponernos los productos que mejor responden a nuestra intención de compra.
Content Curation y podcasting
De todas las cosas que podemos hacer gracias al Machine y Deep Learning y al uso creativo de la Inteligencia Artificial, la más excitante es que con ellos podemos crear cosas que antes hubiera sido extremadamente tedioso y costoso. Por ejemplo, todos sabemos cómo el podcasting ha ido conquistando paulatinamente cuotas de mercado y, ahora, son millones las personas que a diario los escuchan.
Lo que falta, pero, es un sitio web que no solo ofrezca los mejores podcasts por categoría temática (de estos existen muchos), sino que presenten también estos podcasts en su versión transcrita, lo que puede ser de gran ventaja para los usuarios y, además, una manera muy efectiva de posicionar a los podcasts mismos en los resultados de búsqueda para poder adquirir tráfico orgánico y, por ende, contribuir todavía más al número de podcast bajados.
Gracias a herramientas como Import.io, que utilizaríamos para escrapear los listados de los podcasts por categoría y, así, descargarlo de una manera sistemática, y a una herramienta de transcripción automatizada basada en reconocimiento e interpretación del lenguaje natural como es Api.ai, podríamos crear fácilmente unos sitios web basados en la curación de podcasts. Además, también, podríamos sustancialmente utilizar la misma técnica para crear contenidos basados en charlas públicas o transcripciones de videos en YouTube u otra plataforma video.
El poder de los hombres con las máquinas

Los siete ejemplos aquí arriba presentados muestran claramente lo que decíamos antes: la mejor manera de sobrevivir al advenimiento de los bots es trabajar con lo bots, no combatirlos.
Los algoritmos son lo ideal para:
- La recolección de datos;
- La elaboración de datos,
- El análisis objetivo de los datos;
- Para crear propuestas lógicas basadas en datos.
Nosotros, los humanos, por el contrario, somos los ideales para depurar los datos con que se instruyen los algoritmos de Machine y Deep Learning, porque el mayor riesgo de toda tecnología basada en la Inteligencia Artificial es el de no dotar a los algoritmos de todos los datos representativos de lo que queremos que aprendan. Y si un algoritmo tiene datos erróneos o incompletos, el mismo algoritmo ofrecerá resultados erróneos con las consecuencias también trágicas que esto puede significar.
Además de debugger, nuestra función es y será – todavía – la de experimentar y testear las soluciones propuestas por los algoritmos. Por otra parte, gracias al hecho de que los algoritmos nos libran de las tareas más repetitivas y de las que más horas de trabajo nos ocupan, nos dará más tiempo para poder desarrollar nuestra verdadera función de consultores y propulsores del cambio hacía nuestros clientes y nuestras empresas.
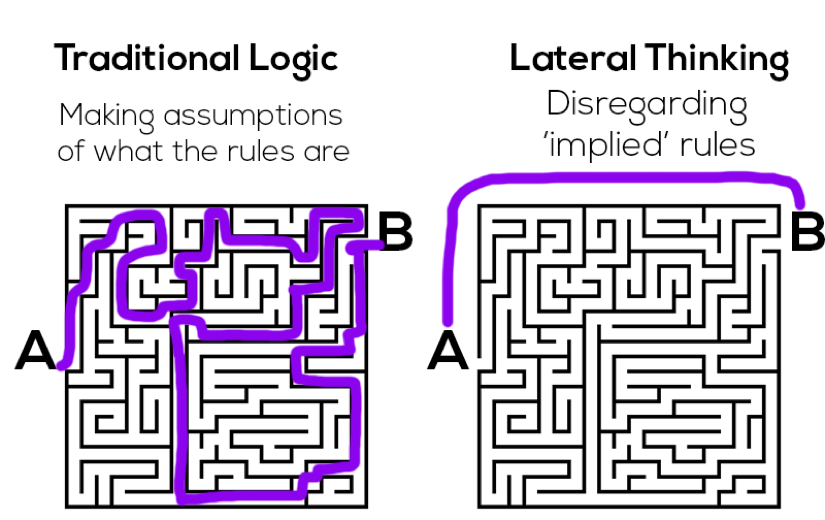
Pero lo más importante es que nosotros, al contrario de los algoritmos, sí que somos naturalmente portados al pensamiento lateral, por lo que – al contrario que los robots – podemos encontrar soluciones creativas a problemas a lo que los algoritmos solamente propones soluciones lógicas:
Los cambios que nos está obligando hacer la irrupción de la Inteligencia Artificial son, por lo tanto, enormes pero excitantes y, sobretodo, nos obligan a repensar de manera radical nuestra función como profesionales del marketing digital.
Volviendo a las series televisivas y al cine que tanto amo, ha llegado el tiempo de abandonar modelos como Don Draper, el hombre de marketing totalmente creativo de Mad Men o de Elliot Anderson, el geek súper técnico de Mr. Robot, para transformarnos en Robert Ford, el creador del mundo de Westworld, un narrador de historias basadas en Inteligencia Artificial.
